1 概述
1.Spark1.2中,Spark SQL开始正式支持外部数据源。Spark SQL开放了一系列接入外部数据源的接口,来让开发者可以实现。使得Spark SQL可以加载任何地方的数据,例如mysql,hive,hdfs,hbase等,而且支持很多种格式如json, parquet, avro, csv格式。我们可以开发出任意的外部数据源来连接到Spark SQL,然后我们就可以通过外部数据源API来进行操作。
2.我们通过外部数据源API读取各种格式的数据,会得到一个DataFrame,这是我们熟悉的方式啊,就可以使用DataFrame的API或者SQL的API进行操作哈。
3.外部数据源的API可以自动做一些列的裁剪,什么叫列的裁剪,假如一个user表有id,name,age,gender4个列,在做select的时候你只需要id,name这两列,那么其他列会通过底层的优化去给我们裁剪掉。
4.保存操作可以选择使用SaveMode,指定如何保存现有数据(如果存在)。
2.读取json文件
启动shell进行测试
1 | //标准写法 |
1 | scala> val df=spark.read.format("json").load("file:///opt/software/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json") |
3 读取parquet数据
1 | val df=spark.read.format("parquet").load("file:///opt/software/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet") |
4 读取hive中的数据
1 | spark.sql("show tables").show |
5 保存数据
注意:
- 保存的文件夹不能存在,否则报错(默认情况下,可以选择不同的模式):org.apache.spark.sql.AnalysisException: path file:/home/hadoop/data already exists.;
- 保存成文本格式,只能保存一列,否则报错:org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 2 columns.;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30val df=spark.read.format("json").load("file:///opt/software/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
//保存
df.select("name").write.format("text").save("file:///home/hadoop/data/out")
结果:
[hadoop@hadoop out]$ pwd
/home/hadoop/data/out
[hadoop@hadoop out]$ ll
total 4
-rw-r--r--. 1 hadoop hadoop 20 Apr 24 00:34 part-00000-ed7705d2-3fdd-4f08-a743-5bc355471076-c000.txt
-rw-r--r--. 1 hadoop hadoop 0 Apr 24 00:34 _SUCCESS
[hadoop@hadoop out]$ cat part-00000-ed7705d2-3fdd-4f08-a743-5bc355471076-c000.txt
Michael
Andy
Justin
//保存为json格式
df.write.format("json").save("file:///home/hadoop/data/out1")
结果
[hadoop@hadoop data]$ cd out1
[hadoop@hadoop out1]$ ll
total 4
-rw-r--r--. 1 hadoop hadoop 71 Apr 24 00:35 part-00000-948b5b30-f104-4aa4-9ded-ddd70f1f5346-c000.json
-rw-r--r--. 1 hadoop hadoop 0 Apr 24 00:35 _SUCCESS
[hadoop@hadoop out1]$ cat part-00000-948b5b30-f104-4aa4-9ded-ddd70f1f5346-c000.json
{"name":"Michael"}
{"age":30,"name":"Andy"}
{"age":19,"name":"Justin"}
上面说了在保存数据时如果目录已经存在,在默认模式下会报错,那我们下面讲解保存的几种模式: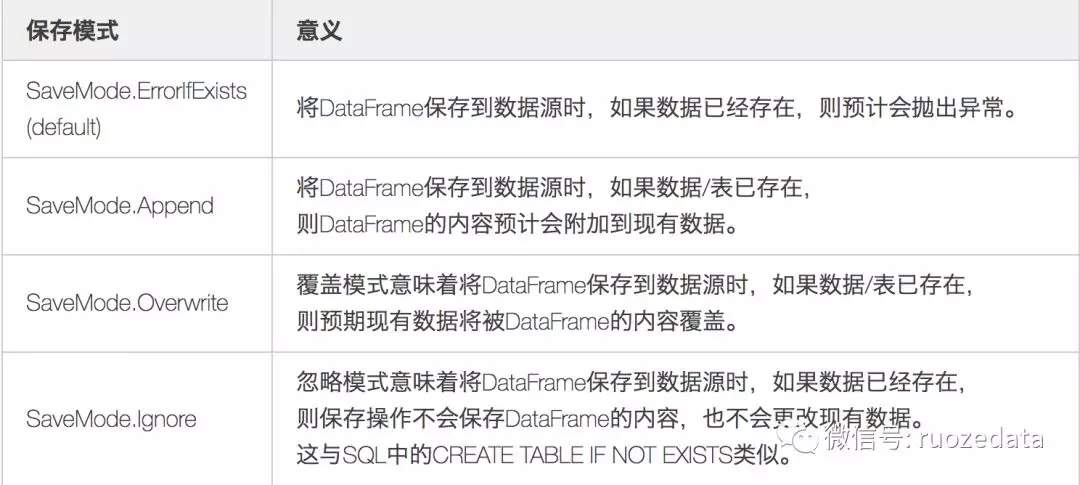
6 读取mysql中的数据
1 | val jdbcDF = spark.read |
7 spark SQL操作mysql表数据
1 | CREATE TEMPORARY VIEW jdbcTable |
8 分区推测(Partition Discovery)
表分区是在像Hive这样的系统中使用的常见优化方法。 在分区表中,数据通常存储在不同的目录中,分区列值在每个分区目录的路径中编码。 所有内置的文件源(包括Text / CSV / JSON / ORC / Parquet)都能够自动发现和推断分区信息。 例如,我们创建如下的目录结构;
1 | hdfs dfs -mkdir -p /user/hive/warehouse/gender=male/country=CN |
我们使用spark sql读取外部数据源:
1 | val df=spark.read.format("json").load("/user/hive/warehouse/gender=male/country=CN/people.json") |
我们改变读取的目录
1 | val df=spark.read.format("json").load("/user/hive/warehouse/gender=male/") |
大家有没有发现什么呢?Spark SQL将自动从路径中提取分区信息。
注意,分区列的数据类型是自动推断的。目前支持数字数据类型,日期,时间戳和字符串类型。有时用户可能不想自动推断分区列的数据类型。对于这些用例,自动类型推断可以通过
spark.sql.sources.partitionColumnTypeInference.enabled进行配置,默认为true。当禁用类型推断时,字符串类型将用于分区列。
从Spark 1.6.0开始,默认情况下,分区发现仅在给定路径下找到分区。对于上面的示例,如果用户将路径/table/gender=male传递给
SparkSession.read.parquet或SparkSession.read.load,则不会将性别视为分区列。如果用户需要指定启动分区发现的基本路径,则可以basePath在数据源选项中进行设置。例如,当path/to/table/gender=male是数据路径并且用户将basePath设置为path/to/table/时,性别将是分区列。
